마지막 주차다
이 주는
화요일까지 논문, 워크플로우 제출
수요일 위클리 프레젠테이션
금요일 최종발표
로 굉장히 바빴다ㅜㅜ
알고리즘
시간관계상 하이퍼파라미터 종류가 많은 xgboost나 adaboost를 쓰는 것 보다 종류가 적은 lr과 랜덤포레스트를 활용하라는 피드백을 받고 이전에 했던 건 그냥 덮기로 했다.

그래도 랜덤포레스트를 계속 시도하던 팀원이 있어서 다행이었다.
나는 lr을 중점적으로 다뤘다.
Logistic Regression

이번에도 유튜브와 지피티를 활용해서 공부해보았다.
박사님께서 lr은 하이퍼파라미터 조정이 필요없고, 컴버지때의 값이 하이퍼파라미터 값이라고 하셨다.
컴버지가 뭐지...아는게 없으니 막막했다.

그래서 TA분께 여쭤봤다.
인도분이셨는데 내 허술한 영어도 친절하게 다 받아주셨고, 설명도 정말 열심히 해주셨다.
여기서 느낀건데 외국인이랑 소통할 때에는 서로의 말을 이해했는지 알기 위해 내가 이해한부분을 다시 말씀드리면서 확인하는 방법이 필수적인 것 같다.
아니면 서로 다른 말을 하는 참사가 발생할 수 있다.
갔다 와서 조원들에게 설명해주고 들은 것을 바탕으로 다시 한번 지피티랑 이야기해보니까 이해가 되었다!

워크플로우는 위와 같다. 하이퍼파라미터 값을 찾을 필요가 없기 때문에 비교적 간단한 것을 볼 수 있다.
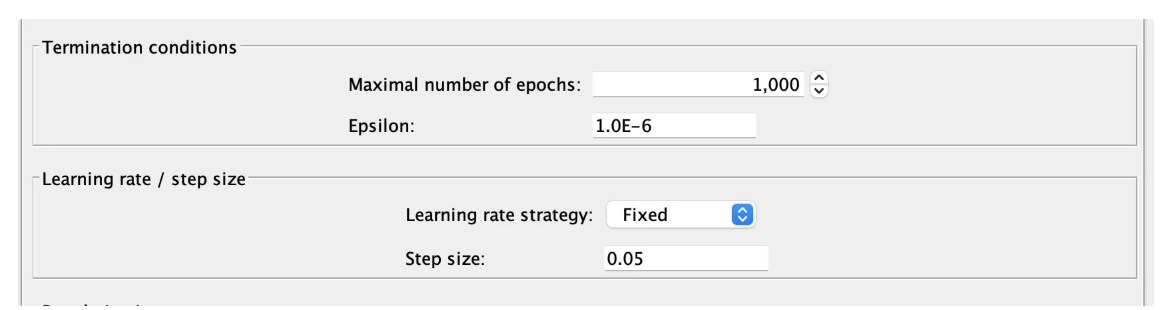
lr에서는 한번 학습할 때마다 이전 턴에 비해서 성능이 얼마나 좋아졌는지(손실함수의 차이 계산)를 계산한다.
이 때의 차이가 epsilon보다 작으면 모델을 종료시켜버린다.
그래서 내가 아무리 maximal number of epochs값을 많이 잡아도, 모델이 학습하는 횟수는 제한적이게 되는 것이다!

여기를 보면 iterations가 학습한 횟수이다. 이 모델은 내가 1000으로 잡았음에도 525회밖에 돌지 않았다.
다른 조도 converge 값을 찾기에 어려움을 겪고있었는데 박사님이 우리조한테 물어보라고 하셨다고 했다.
박사님이 원하시는 것을 해낸 것 같아서 좀 뿌듯했다 : )

성능은 위와 같이 별로 좋진 않다.
하지만 이 모델은 랜덤포레스트 모델과 비교하기 위한 모델이므로 여기서 마무리했다!
Random Forest
우리의 메인 알고리즘이 되어버린 랜덤포레스트이다
워크플로우

워크플로우는 위와 같다.
4주차 피드백을 받고, 하이퍼파라미터 값을 알아보기 위한 parameter optimization loop 노드를 추가하였고, 과적합 여부를 알아보기 위해서 test set에 대한 score과 traing set에 대한 score을 각각 알아보도록 재설계했다.
하이퍼파라미터
하이퍼파라미터 값은 parameter optimization loop 노드를 통해서 찾았다.

우선 depth와 min_node를 조절하면서 가장 좋은 값을 찾고자 하였고
number of trees는 500으로 고정하였다.
depth는 각 트리의 깊이를 의미한다. 이 값이 증가할수록 성능이 좋아지지만 과적합의 위험이 있다.
또한 min_node는 리프(leaf) 노드가 되기 위한 최소 샘플 개수를 의미한다. 이 값이 작을수록 성능이 좋지만, 너무 작으면 작은 데이터조각까지 학습하기때문에 과적합의 위험이 있다.
위와 같이 parameter optimization loop start에서 하이퍼파라미터의 값의 범위를 설정하고

random forest learner 노드 내의 flow variables에서 위와 같이 설정해주면 해당 범위 모두를 돌게 된다.(정말 오래걸린다)
이 때의 결과값을 csv writer 노드를 통해 파일로 저장하면

이런식으로 csv 파일로 깔끔하게 정리된다.
그 다음 하이퍼파라미터값을 찾기 위해서

accuracy를 기준으로 위와 같이 엑셀로 값의 분포를 확인했다.
전반적으로 좌측 하단으로 갈수록 accuracy가 높아지는 것을 볼 수 있었다.
하지만 우리는 단순히 성능이 좋은 것만을 기준으로 하이퍼파라미터값을 뽑는 것이 아니라 과적합 여부도 확인해야한다.

따라서 test set 표 중 이 패턴이 무너지는 부분을 찾았다. 위 그림에서는 0.7786이라고 볼 수 있다.
하지만 우리는 안정성을 위해서 한 칸 뒤에 있는 값을 하이퍼파라미터값으로 설정하였다.
CFD와 SFD
여기서 cfd와 sfd를 사용한 모델의 성능을 비교하라고 하셨다.
cfd는 개발자가 선정한 피쳐들로 이루어진 데이터셋을 말하고, sfd는 모델을 돌려서 나온 수치화된 피쳐의 중요도를 통해서 피쳐를 선정하는 방식이다.
우리는 이제까지 cfd를 이용해서 모델을 만들었던 것이다! 따라서 sfd를 사용해서 모델을 돌려보기 위해서 피쳐중요도를 알아보았다
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 1️⃣ 데이터 로드 (Iris 데이터셋 예제)
data = pd.read_csv('/content/label_encoding (1).csv')
X = data.drop(columns=['Booking_Cancellation'])
y = data['Booking_Cancellation']
# 2️⃣ 데이터 분할 (Train/Test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 3️⃣ RandomForest 모델 학습
rf_model = RandomForestClassifier(n_estimators=500, criterion="gini", max_depth=16, min_samples_leaf=8)
rf_model.fit(X_train, y_train)
# 4️⃣ Feature Importance 계산
feature_importance = rf_model.feature_importances_
# 5️⃣ 결과를 DataFrame으로 정리
importance_df = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importance})
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# 6️⃣ 중요도 시각화
plt.figure(figsize=(10, 5))
plt.barh(importance_df['Feature'], importance_df['Importance'], color='skyblue')
plt.xlabel("Feature Importance")
plt.ylabel("Feature Name")
plt.title("Feature Importance in Random Forest")
plt.gca().invert_yaxis() # 중요도가 높은 순으로 정렬
plt.show()
# 7️⃣ 중요도 출력
print(importance_df)
간단하게 우리의 종속변수와 하이퍼파라미터 값들을 설정하고 코드를 코랩을 사용해서 돌려보았다.

결과는 위와 같이 나왔다.
우리는 상위 8개 피쳐를 사용해서 sfd를 구성하였다.



위와 같이 random forest에서는 전반적으로 sfd가 cfd보다 좋은 성능을 낸다는 것을 알 수 있었다.
하지만 logistic regression에서는 sfd로 만든 모델이 더 좋지 않은 성능을 보였다.
논문

완성본은 아니지만 3페이지짜리 논문 초안은 완성했다.
논문은 lr 과 random forest 알고리즘을 사용한 모델의 비교와 sfd를 사용한 모델과 cfd를 사용한 모델을 비교하는 내용이 주를 이룬다.
슈퍼컴퓨터센터
아 중간에 샌디에이고 슈퍼컴퓨터센터에 견학을 갔다.




내부는 엄청 시끄러웠는데 엄청 신기했다.
직원분이 슈퍼컴퓨터에 대해서 정말 열심히 설명해주셨는데
좀 어려웠다...
수료
드디어 수료식을 했다.


수료증이 예뻐서 기분이 좋았다.


끝나고 열심히 가르쳐주신 선생님들과 사진도 찍고 이야기도 나누었다!
회고
사실 5주가 정말 후딱 갔다.
우선 내가 평생 해볼 일 없다고 선언했던 인공지능을 5주간 해보니 뭐 생각했던 것보다는 할만했던 것(?) 같기도 하다.
확실한건 내가 하기 싫은 분야라도 열심히 하면 뭐든 된다는 것! 어쩌다보니 인공지능 논문의 1저자가 된 것 처럼 말이다
그리고 하기 싫은 분야도 해봐야 지금 하고있는 분야의 소중함을 더 깨닫게 되는 것 같다. 미국 가기 전에 슬슬 백엔드 분야가 지루하다고 생각한 적이 있는데 이제는 감사해하면서 공부할 수 있을 것 같다.
또 영어 관련 능력을 얻었다! 사실 실력을 얻었다고 보긴 좀 그렇고 그냥 틀리면 어때 난 한국인인데 라는 마인드로 영어로 이런 저런 대화를 많이 시도하보니 머릿속에 있는 영어들을 최대한 활용해서 대화하기가 가능해진 것 같다. 특히 TA님들께 프로젝트 내에서 궁금한 것을 물어볼 때 처음에는 못알아들으실까봐, 틀릴까봐 한마디한마디 조심했었는데, 나중에는 생각보다 대화가 잘된다는 것을 알고 자연스럽게 말할 수 있게 되었다.
그리고 나는 초등학교때부터 영어로 발표하는 것을 매우매우 두려워했었다. 한국어로 쓴 발표대본을 까먹으면 그냥 막 말하면 되지만, 영어대본을 까먹으면 할 말이 없기 때문이다. 하지만 여기 와서 5주간 총 6번의 영어 발표를 하면서 나름의 요령이 생겼고, 이제 더이상 영어 발표가 막 두렵거나 하진 않은 것 같다.
마지막으로 내가 1저자가 되면서 마지막 2주간 거의 팀원들을 이끌어보았는데, 팀원들과 좋은 성과를 내기 위해서는 내가 팀원들에게 원하는 것을 정확하게 문서화하는 것의 중요성을 깨달았다. 처음에는 거의 말로만 했었는데, 문서화를 통해 내가 원하는 것을 정확히 알려주니까 더욱 좋은 결과물이 나왔다!
비록 5주간 우여곡절이 많았지만 우리 조 모두 현명하게 해쳐나간 것 같아서 자랑스럽고 고맙다!
앞으로 논문 더 써야하는데 잘 할 수 있을 것 같다
'UCSD Qualcomm Institute > AI Project' 카테고리의 다른 글
| UCSD에서 살아남기 (5) | 2025.02.26 |
|---|---|
| UCSD Qualcomm Institute AI Project 4주차 (1) | 2025.02.23 |
| UCSD Qualcomm Institute AI Project 3주차 (4) | 2025.02.08 |
| UCSD Qualcomm Institute AI Project 2주차 (1) | 2025.01.28 |
| UCSD Qualcomm Institute AI Project 1주차 (1) | 2025.01.28 |



