Hire Higher 프로젝트는 카카오테크캠퍼스에서 우수상을 수상한 프로젝트이다.
현업 개발자님들과 열심히 하는 팀원들 덕분에 참 많이 성장하고 즐거웠던 것 같다.

프로젝트 소개
이 프로젝트는 외국인 노동자를 위한 서비스이다.
https://ethereal-coder.tistory.com/236
[기획 프로젝트] Hire Higher - 외국인 노동자를 위한 구인구직 서비스
카카오테크캠퍼스 3단계를 앞두고 아이디어톤 행사가 열렸다. 아이디어톤 행사 3일 전에 팀이 정해졌고, 아이디어 초안을 정한 후 피드백을 받고 이를 바탕으로 하여 아이디어톤에서 서비스를
ethereal-coder.tistory.com
자세한 기획은 여기서 확인할 수 있다.
간단하게 설명하자면, 우리는 외국인 노동자를 구인할 때 근로계약서를 작성하지 않아서 생기는 문제점에 주목했다.
따라서 하나의 서비스에서 구인,구직과 근로계약서를 동시에 작성하도록 하였다.

메인페이지에서는 위와 같이 현재 구인중인 공고글이 뜬다.
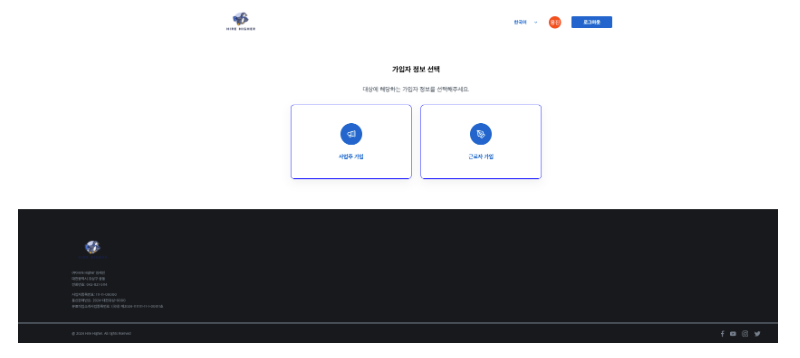
가입할 때에는 위와 같이 사업주와 근로자의 가입을 따로 받는다.
사업주 시점


사업주는 위와 같이 회사를 등록하고, 근로계약서에 들어갈 사인을 등록할 수 있다.


또한 구인글을 등록하고, 해당 구인글에 지원한 지원자를 확인할 수 있다.
근로자 시점

근로자는 위와 같이 베트남어로 서비스를 이용할 수 있다.

근로자는 위와 같이 이력서를 작성하고 근로계약서에 들어갈 사인을 등록할 수 있다.
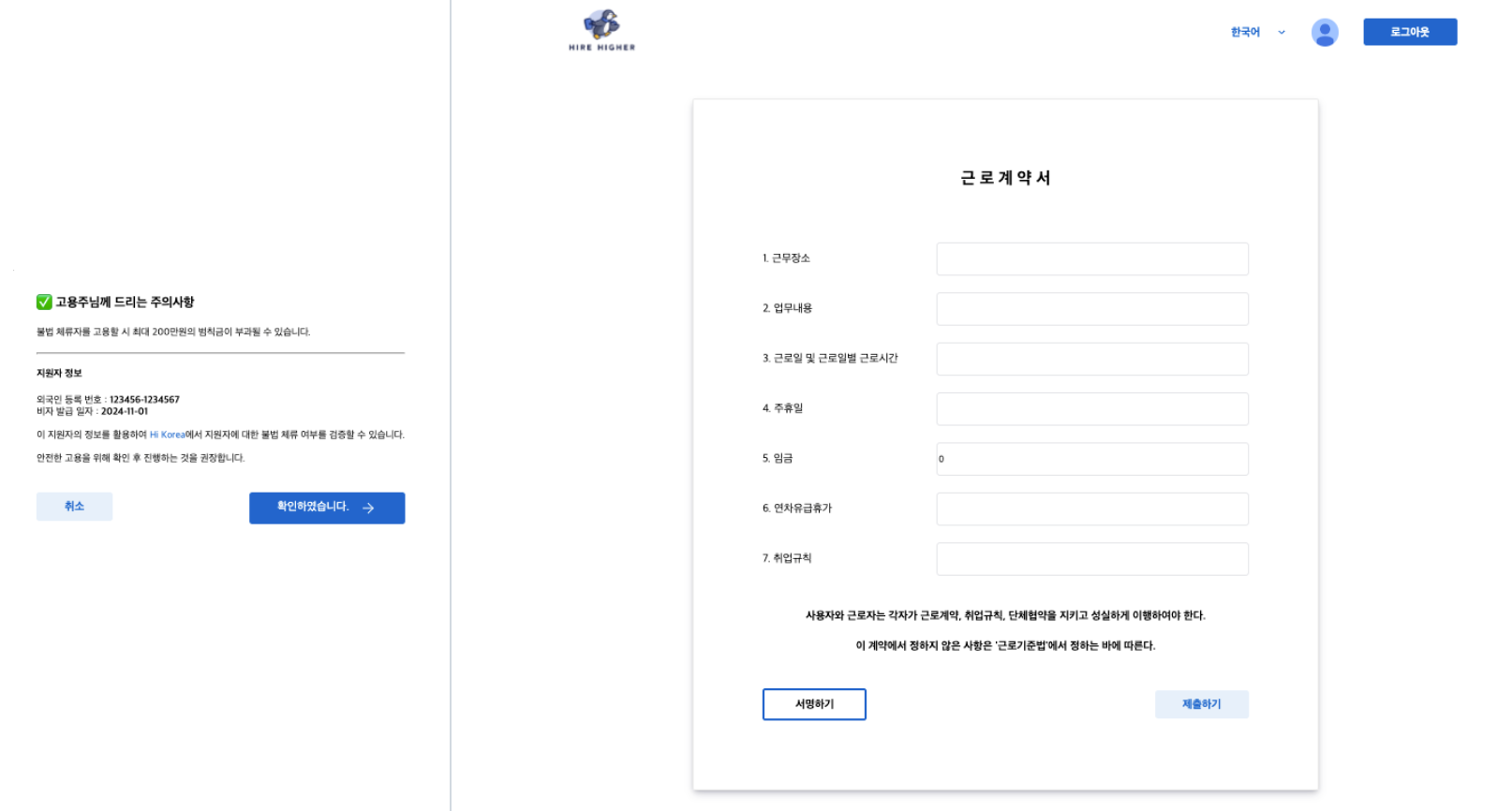
또한 불법체류자 고용을 방지하기 위해 외국인 등록번호와 비자발급일자를 등록하도록 하고,
근로계약서를 작성하면 저절로 pdf로 저장되어 근로자와 사업주가 각각 가지고 있을 수 있도록 하였다.
아키텍처

아키텍처는 위와 같다.
우리는 비용절감을 위해서 gcp를 사용하였다.
소통방식
우리는 프론트엔드 4명과 백엔드 4명으로 구성되어있었다.
전체 회의는 매주 월요일 7시에 하였고, 백엔드끼리의 회의는 그때그때 정해서 했다.
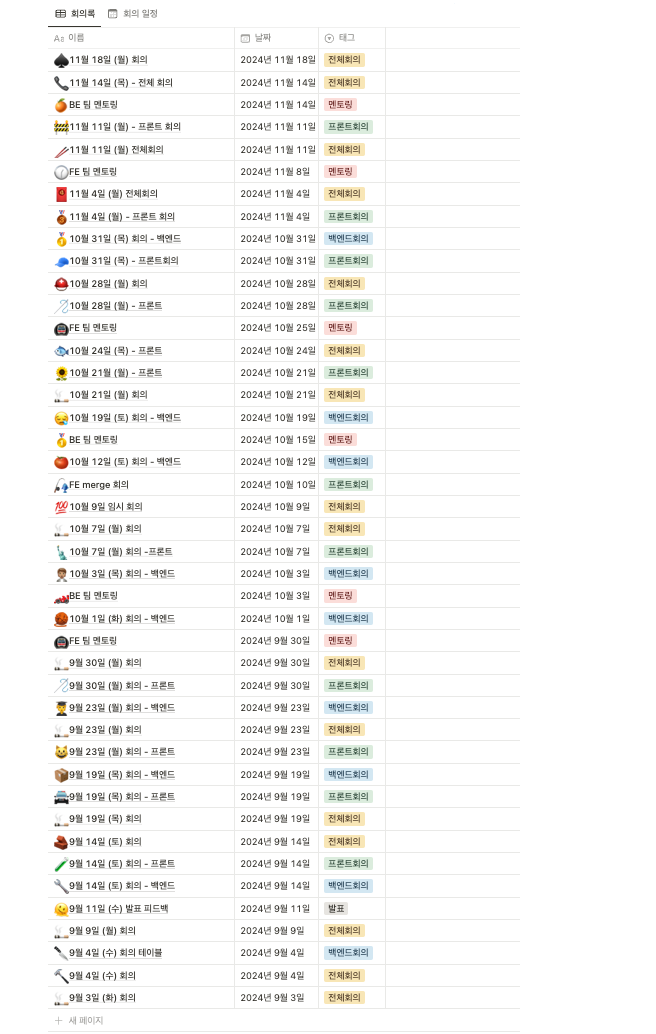
우리의 회의록이다. 회의록은 프론트, 백 전체회의 , 멘토링을 모두 한 곳에 정리하여 모두가 볼 수 있도록 하였다.
회의 전에 위와 같이 각자 회의 때 논의해야 할 내용을 적고 회의 때 차례로 해결해나가는 방향으로 진행했다

또한 위와 같이 규칙을 설정하고 모두 지키도록 노력하였고
다양한 문서를 체계적으로 관리하였다.
ERD설계
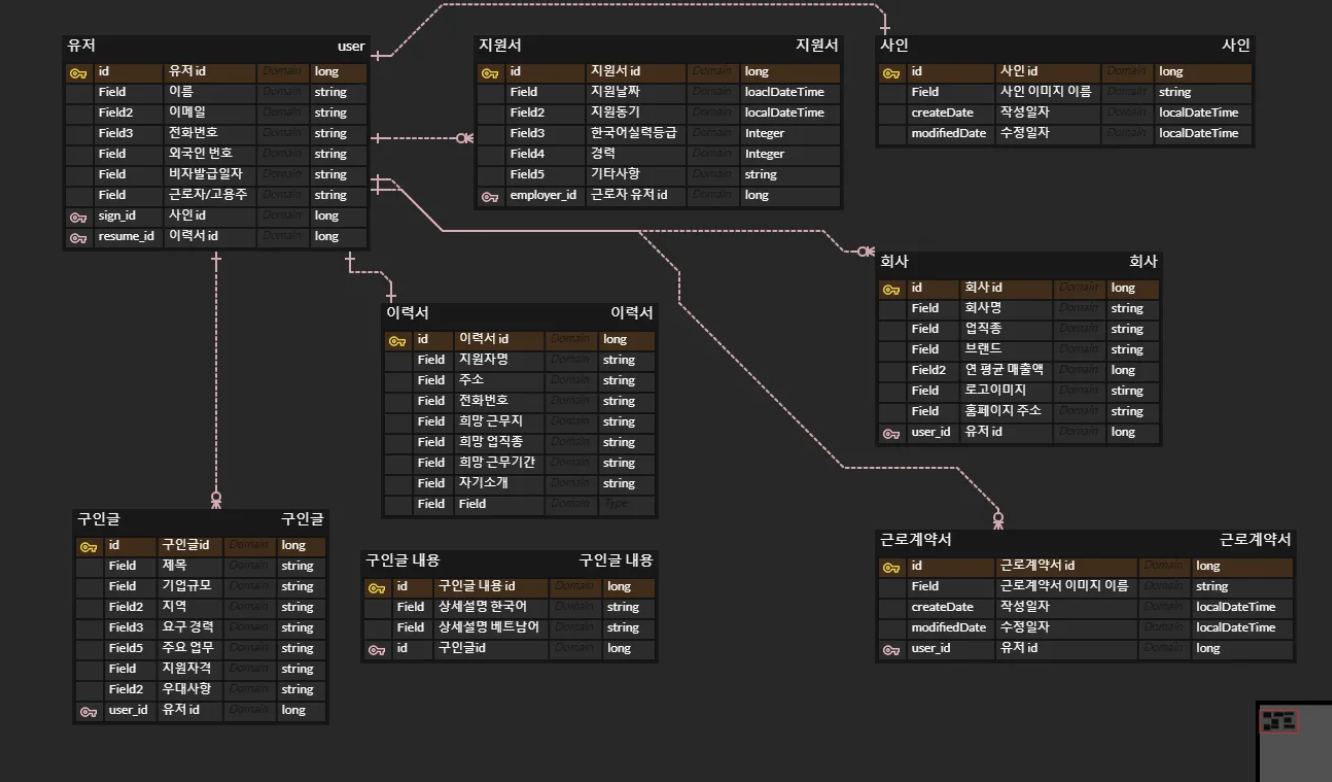
ERD 초안은 위와 같다.
하지만, 멘토님의 피드백을 들어보니까 문제점이 많았다.
- 근로자와 고용주 모두 USER 엔티티를 사용 -> 이렇게 하면 각각을 위한 필드가 모두 들어가서 테이블이 무거워진다
- 구인글 테이블을 고용주와 연결했는데 회사가 많을 경우에는 어떤 회사의 구인글인지 구분이 불가능하다
- 전체적으로 깔끔하지 않다
그래서 프론트엔드, 백엔드 회의를 거친 후 만들어진 최종적인 ERD는
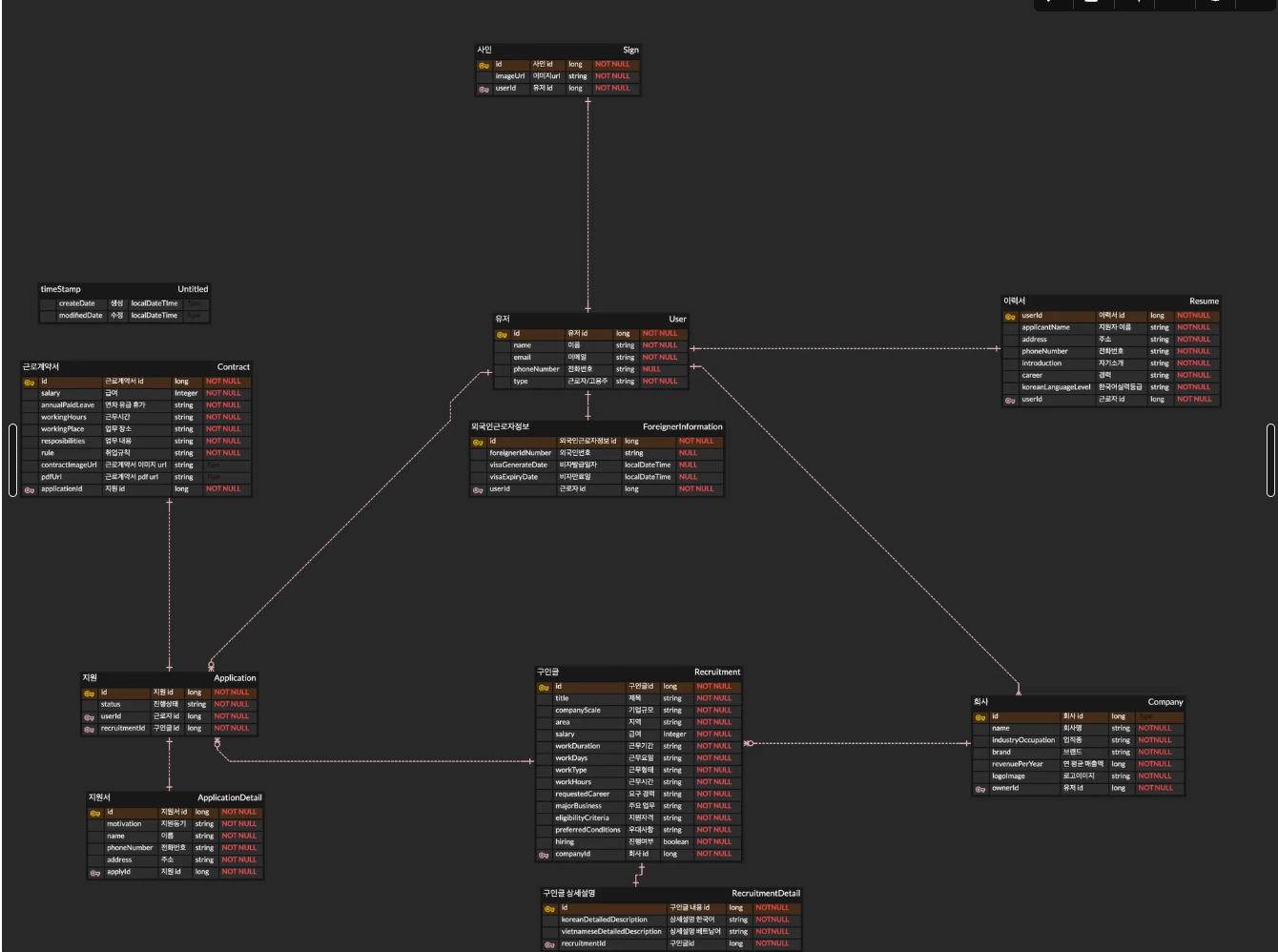
이렇게 만들어졌다.
개발을 하다보면 수정사항이 많이 생겼는데 그럴 때마다 ERD를 수정하고 보고를 했다.
API명세

API는 위와 같이 노션에서 관리했다.
필드 등의 변경사항이 생기면 수정 후 프론트 분께 알렸고
배포 후 프론트분들이 테스트를 하시고 성공하면 위와 같이 체크 이모티콘을 적어주셨다.
개발
우리 팀은 도메인 단위로 각자의 역할을 나누었다.
나는 이력서와 구인글 부분을 담당했다
CRUD

curd는 위와 같이 기본적인 방식으로 구현하였다.
본 글에서는 CRUD에 대한 내용은 잘 다루지 않을 것이다.
Repository는 JPA를 이용해서 구현하였다.
인증
이전에는 user 관련 repository에서 직접 회원의 id등의 정보를 통해서 직접 조회하는 방식으로 진행했었다.
하지만 이번에는 OAUTH를 구현해주시는 분이 어노테이션을 만들어주셔서 훨씬 깔끔한 코드로 인증을 할 수 있었다.

이런 식으로 헤더로 토큰을 받는 api에서
@Operation(summary = "이력서 저장 메서드")
@PostMapping
public ResponseEntity<Void> saveResume(
@RequestBody ResumeRequest resumeRequest,
@LoginUser User user
) {
resumeService.saveResume(resumeRequest, user);
return new ResponseEntity<>(HttpStatus.CREATED);
}이와 같이 어노테이션으로 바로 User엔티티를 가져올 수 있다.
구인글 저장
vertical partitioning
구인글은 베트남어랑 한국말로 제공되어야한다.
그런데 이 부분을 프론트분들과 협의해 본 결과, 우리가 보낸 데이터를 프론트에서 번역해서 화면에 보여주기는 어려울 것 같다는 안타까운 소식을 들었다.
그래서 우리는 DB에 구인글을 한국어와 베트남어로 모두 저장해야했다.
만약 한 테이블 내에 한국어와 베트남어의 구인 내용이 모두 들어간다면 테이블이 너무 무거워질 수 있기 때문에 이를 분리하는 vertical partitioning을 사용하였다.

AI로 구인글 요약하고 번역하기
구인글에는 제목, 기업규모, 지역....다양한 필드들이 있다.
하지만 이들을 모두 번역하려면 openAi api호출을 필드마다 해야했고, 그렇게 하면 필드 수가 너무 많아지는 문제가 있었다.
그래서 ai로 구인글의 내용을 모두 요약하고 이를 한번에 번역하도록 구현하였다.
public String summation(RecruitmentRequest recruitmentRequest) throws JsonProcessingException {
return getResponseFromAi(recruitmentRequest.toString() + " 를 한국말로만 자연스럽게 요약해줘");
}
public String translateKoreanToVietnamese(String message) throws JsonProcessingException {
return getResponseFromAi(message + " 라는 말을 베트남어로 번역해주는데, 딱 베트남어만 리턴해줘");
}위와 같이 OpenAiService 클래스를 만들고 그 안에 openAi에 요청을 하고 응답을 받는 코드를 구현하였다.
이 때 한국어를 베트남어로 번역하는 메서드와 구인글을 요약하는 메서드를 만들어 각각의 요청사항을 ai에 전달하도록 하였다.
public Long saveRecruitment(RecruitmentRequest recruitmentRequest)
throws JsonProcessingException {
String koreanTitle = recruitmentRequest.title();
String vietnameseTitle = openAiService.translateKoreanToVietnamese(koreanTitle);
String koreanDetailedDescription = openAiService.summation(recruitmentRequest);
String vietnameseDetailedDescription = openAiService.translateKoreanToVietnamese(
koreanDetailedDescription);
RecruitmentContent recruitmentContent = recruitmentContentRepository.save(
new RecruitmentContent(koreanDetailedDescription, vietnameseDetailedDescription));
return recruitmentRepository.save(
recruitmentMapper.toRecruitment(koreanTitle, vietnameseTitle, recruitmentRequest,
recruitmentContent, companyRepository.findById(recruitmentRequest.companyId())
.orElseThrow(() -> new NoSuchElementException("해당하는 회사가 존재하지 않습니다.")), true,
new Date()
)).getRecruitmentId();
}위 코드에서 구인글 제목을 베트남어로 번역한 것과 구인글을 요약하고 번역한 내용을 RecruitmentRepository에 저장한다
구인글 전체조회
DTO로 데이터 가공 / 페이지네이션
구인글 전체조회로 보내는 데이터는 메인페이지에 구인글 목록으로 들어간다.
따라서 구인글 전체를 보내는 것이 아니라, 구인글의 일부 정보(회사, 제목...)만 보내야했다.
또한 처음에는 무한스크롤로 메인페이지를 구현하고자 했었는데 옛날 구인글을 보고자 하는 사람에게는 불편할 수 있다는 멘토님의 의견을 듣고 페이지네이션까지 구현해야하게 되었다.
public record RecruitmentSummationResponse(
Long recruitmentId,
String imageUrl,
String koreanTitle,
String vietnameseTitle,
String companyName,
Long salary,
String area,
String workHours
) {
}우선 이와 같이 메인페이지에 보낼 구인글 DTO를 만들고,
@Operation(summary = "구인글 전체 조회 메서드")
@GetMapping("/all")
public ResponseEntity<RecruitmentAllResponse> getAllRecruitments(
@RequestParam int page
) {
int fixedPageSize = 4;
Pageable pageable = PageRequest.of(page, fixedPageSize);
return ResponseEntity.ok().body(recruitmentService.getAllRecruitment(pageable));
}페이지네이션을 구현하기 위해 controller에 위와 같은 메서드를 구현했다.
페이지네이션은 클라이언트 기준 0페이지를 받으면 1페이지를 요청하고, 1페이지를 받으면 2페이지를 요청하는 식으로 진행된다.
따라서 현재 클라이언트에서 원하는 페이지가 뭔지 알기 위해 @RequestParam으로 page변수를 얻도록 했다
또한 한 페이지에 들어갈 데이터 수는 4로 고정해두고, 이를 통해 pageable 객체를 생성했다.
이를 service에 넘긴다.
public RecruitmentAllResponse getAllRecruitment(Pageable pageable) {
Page<Recruitment> recruitments = recruitmentRepository.findAllByHiringTrue(pageable);
List<RecruitmentSummationResponse> recruitmentSummationResponseList =
recruitments.stream()
.map(recruitment -> new RecruitmentSummationResponse(
recruitment.getRecruitmentId(),
recruitment.getCompany().getLogoImage(),
recruitment.getKoreanTitle(),
recruitment.getVietnameseTitle(),
recruitment.getCompanyName(),
recruitment.getSalary(),
recruitment.getArea(),
recruitment.getWorkHours()
))
.collect(Collectors.toList());
int totalPage = recruitments.getTotalPages();
return new RecruitmentAllResponse(recruitmentSummationResponseList, new PageDto(totalPage));
}service에서는 받은 pageable로 repository에 값을 요청한다.
그 다음 받은 값을 stream을 통해서 다시 RecruitmentSummationResponse로 바꾼다.
이 때 프론트 측에서 전체 페이지 수를 알아야하니, 그 값을 달라고 요청해주셔서 해당하는 값을 RecruitmentAllResponse로 변환하여 응답하였다.
public record RecruitmentAllResponse(
List<RecruitmentSummationResponse> content,
PageDto pageable
) {
}이렇게 하면 요약된 데이터의 리스트와 전체 페이지 수가 프론트측에 넘어가게 된다
데이터 정렬 / 원하는 데이터만 반환하기
우리는 메인페이지에서 급여순 정렬, 최신순 정렬 기능을 제공한다.
이 기능 역시 백엔드에서 해결해주기로 하였다.
@Operation(summary = "최근 올라온 구인글 순서대로 정렬")
@GetMapping("/latestRegistration")
public ResponseEntity<RecruitmentAllResponse> getAllRecruitmentsLatestRegistration(
@RequestParam int page
) {
int fixedPageSize = 4;
Pageable pageable = PageRequest.of(page, fixedPageSize);
return ResponseEntity.ok().body(recruitmentService.getAllRecruitmentAndSortByDate(pageable));
}
@Operation(summary = "급여 높은 순서대로 정리해서 전체 구인글 반환하는 메서드")
@GetMapping("/salary")
public ResponseEntity<RecruitmentAllResponse> getAllRecruitmentsSalary(
@RequestParam int page
) {
int fixedPageSize = 4;
Pageable pageable = PageRequest.of(page, fixedPageSize);
return ResponseEntity.ok().body(recruitmentService.getAllRecruitmentAndSortBySalary(pageable));
}이러한 기능을 원할 때를 대비해서 따로 api를 만들었다.
여기로 요청이 오면 service에서는 각각에 맞는 repository에 요청을 해서 해당 데이터를 가져온다.(이외의 과정은 모두 위와 일치한다)
public interface RecruitmentRepository extends JpaRepository<Recruitment, Long> {
List<Recruitment> findByCompany(Optional<Company> company);
Page<Recruitment> findAllByHiringTrueOrderBySalaryDesc(Pageable pageable);
Page<Recruitment> findAllByHiringTrueOrderByUploadDateDesc(Pageable pageable);
Page<Recruitment> findAllByHiringTrue(Pageable pageable);
}repository는 간단하게 JPA를 통해서 구현이 가능했다.
ByHiringTrue -> Hiring 필드가 True인 데이터만 추출
By~Desc -> ~필드를 기준으로 내림차순 정렬
구인글 마감
우리는 구인구직이 성사되면 자동으로 해당 구인글을 마감하도록 설정하였다.
따라서 나는 구인글 마감 필드를 만들어서 해당 요청이 오면 이를 False로 바꿈으로서 해당 구인글에 마감처리를 한다.
@Operation(summary = "구인글 마감 메서드")
@PostMapping("/hiringClose/{recruitmentId}")
public ResponseEntity<Void> setRecruitmentHiringFalse(
@PathVariable Long recruitmentId
) {
recruitmentService.setRecruitmentHiringFalse(recruitmentId);
return ResponseEntity.ok().build();
}이건 간단하게 Setter을 사용해서 구현하였다
이력서 조회
개발을 하다보니 이력서와 지원서에서 겹치는 내용이 많아서 사업주가 읽을 때 불편한 점이 있을 것이라고 생각했다.
따라서 클라이언트가 이력서와 지원 id를 주면, 백엔드에서 지원서 속 지원동기 데이터를 뽑아서 함께 반환하는 기능을 구현했다.
@Operation(summary = "이력서 id로 이력서 조회 메서드")
@GetMapping("/{resumeId}/{applyId}")
public ResponseEntity<ResumeAndApplyResponse> getResumeById(
@PathVariable Long resumeId,
@PathVariable Long applyId,
@LoginUser User user
) {
return ResponseEntity.ok().body(resumeService.findResumeById(resumeId, applyId));
}이력서와 지원id를 api를 통해서 받고,
public ResumeAndApplyResponse findResumeById(Long resumeId, Long applyId) {
Resume resume = resumeRepository.findById(resumeId)
.orElseThrow(() -> new NoSuchElementException("해당하는 이력서가 존재하지 않습니다."));
Apply apply = applyRepository.findById(applyId)
.orElseThrow(() -> new NoSuchElementException("해당하는 지원이 존재하지 않습니다."));
ApplicationForm applicationForm = applicationFormRepository.findByApply(apply)
.orElseThrow(() -> new NoSuchElementException("해당하는 지원서가 존재하지 않습니다."));
return resumeMapper.toResumeAndApplyResponse(resume, applicationForm.getMotivation());
}Service에서 지원 조회 -> 지원서 조회로 지원동기 데이터를 얻어서 이를 한번에 반환하도록 하였다.
에러처리
나는 이력서가 이미 존재하는 사용자가 이력서를 또 저장하고자 할 때 에러메세지를 보낸다.
if (resumeRepository.findByUser(user) != null) {
throw new ResumeAlreadyExistsException("해당 유저에 대한 이력서가 존재합니다.");
}이 부분이다!
이 때 나는 ResumeAlreadyExistsException 에러를 생성하여 보내도록 하였다.
public class ResumeAlreadyExistsException extends RuntimeException {
public ResumeAlreadyExistsException() {
}
public ResumeAlreadyExistsException(String message) {
super(message);
}
}super(message) 를 통해서 에러와 함께 개발자가 지정한 메세지도 함께 보내도록 했다.
문제해결/ 고민한 점
Mapstruct 사용
우리는 보안상의 이유 등으로 repository한테 받은 데이터를 바로 클라이언트에게 보내지 않고 DTO로 변환해서 보낸다.
처음에는 이를 매핑하는 메서드를 service단에 직접 만들어서 구현했는데 뭔가 이 기능이 service단에 있는게 맞나라는 생각도 들고, 전반적으로 지저분해보이는 것을 발견할 수 있었다.
이 문제를 멘토님께 말씀드리니 mapstruct를 사용하는 것을 추천해주셨다.
구현 방법은 생각보다 간단했다
package team18.team18_be.resume.mapper;
import org.mapstruct.Mapper;
import org.mapstruct.factory.Mappers;
..
@Mapper(componentModel = "spring")
public interface ResumeMapper {
ResumeMapper INSTANCE = Mappers.getMapper(ResumeMapper.class);
ResumeResponse toResumeResponse(Resume resume);
ResumeAndApplyResponse toResumeAndApplyResponse(Resume resume, String motivation);
Resume toResume(ResumeRequest resumeRequest, User user);
}위와 같이 Mapper 어노테이션을 붙이고, INSTANCE를 선언한다.
그 다음
변환할타입(클래스명) 메서드명(변환될 타입)을 선언해주기만 하면 된다.
이 때 주의할 점은 변환할 타입과 변환될 타입의 필드명이 일치해야한다는 것이다.
또한 변환될 타입 내부에 존재하지 않은 필드를 사용해서 사용할때에는
ResumeAndApplyResponse toResumeAndApplyResponse(Resume resume, String motivation);위와 같이 매개변수를 하나 더 선언해주면 된다.(이 때 이 매개변수의 필드명은 변환될 타입의 필드명과 동일해야함)
사용할 때에는 의존성 주입으로 만들어 둔 Mapper을 주입받고,
public ResumeResponse findResumeByEmployee(User user) {
return resumeMapper.toResumeResponse(resumeRepository.findByUser(user));
}위와 같이 해당 메서드를 호출하기만 하면 된다.
@Lob사용
내가 관리한 도메인 중 지원동기 등등 긴 글로 쓸 수 있는 데이터들이 있었는데 내가 이들을 처음에는 그냥 String으로 선언했었다.
하지만 이렇게 하면 JPA가 쿼리문을 만들 때 VARCHAR타입으로 선언한다고 한다.
VARCHAR은 255자밖에 수용을 못하기때문에 우리는 이를 BLOB나 CLOB로 선언하도록 해야한다.
이를 위한 해결책은
@Lob
private String selfIntroduction;
그냥 간단하게 엔티티 클래스 내 필드에 @Lob어노테이션을 붙여주는 것이다.
깃허브 사용
https://ethereal-coder.tistory.com/261
[git] 깃허브 정리
깃허브란분산 버전 관리 툴인 깃을 사용하는 프로젝트를 지원하는 웹호스팅 서비스 깃이란컴퓨터파일의 변경사항을 추적하고 여러 명의 사용자들 간에 해당 파일들의 작업을 조율하기 위한
ethereal-coder.tistory.com
프로젝트를 해보니 깃허브 사용에 많이 능숙하지 않은 나를 발견하였다.
그래서 관련 내용을 따로 공부하고 정리했다.
패키징
AI를 활용한 번역 기능이 구인글에 사용되기는 하지만, 다른 도메인에서도 번역 기능이 필요할 수 있다는 점에서 외부 API를 사용하여 번역하는 메서드를 어느 패키지에 넣어야 할지 고민이 있었다.
멘토님의 조언을 받아, 번역 로직을 특정 도메인에 종속시키지 않고 재사용성을 높이기 위해 infrastructure 패키지를 따로 만들어 그 안에 AI와 통신하는 데 필요한 DTO와 클래스들을 배치했다. 이로써 코드 구조가 더 명확해졌고, 번역 기능이 다른 도메인에서 필요할 때도 손쉽게 확장할 수 있는 기반을 마련할 수 있었다.
느낀 점
이번 프로젝트를 통해서 팀프로젝트에 있어서 중요한 것들을 많이 배운 것 같다.
일단, 내가 생각하기에 가장 중요한 것은 모든 팀원들이 마음 편하게 각자의 의견을 이야기 할 수 있는 분위기인 것 같다.
우리 팀에서는 내가 나이가 제일 어렸는데 다른 팀원분들이 정말 편안한 분위기를 만들어주셨다. (내가 회의때마다 너무 웃어서 엄마가 친구랑 영상통화하는 줄 아실 정도..)
그래서 나를 비롯한 모든 팀원분들이 의견을 편하게 나눌 수 있었고, 그 덕분에 프로젝트가 한층 탄탄해 질 수 있었던 것 같다.
또한 내가 생각보다 실수가 많은 사람이라는 것도 알게되었다. 단순히 코드가 잘 돌아가는 것을 신경쓰고 구현했는데, 알고보면 API명세서와 다른 필드명을 쓰고있었다던가.. 하는 실수가 있었다. 개발 초,중반에는 전혀 문제가 없었는데 배포하고 합칠 때 문제가 좀 있었어서 너무너무 죄송했다.
프론트분들은 내 코드를 보고 개발하는 것이 아닌, 우리가 공통으로 관리하는 문서를 통해 개발하신다는 것을 무조건 기억하고 주기적으로공통문서와 내 코드를 비교하는 습관을 가져야겠다.
또한 우리는 감사하게도 멘토님이 계셨는데, 멘토님께 궁금한 점을 적극적으로 여쭤보고 수용할 때마다 프로젝트의 퀄리티가 올라가는 것을 느낄 수 있었다. 앞으로도 부끄러워하지 말고 적극적으로 주변 사람들께 조언을 구하는 자세를 가져야겠다고 다짐했다.
'프로젝트 > 프로젝트 정리' 카테고리의 다른 글
| [개발 프로젝트] JUSTTALK (2) | 2024.11.28 |
|---|---|
| [기획 프로젝트] Hire Higher - 외국인 노동자를 위한 구인구직 서비스 (0) | 2024.08.31 |
| [백엔드 프로젝트] F!LB - AI가 알려주는 객관적인 감정인식 (3) | 2024.08.30 |


